
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
- SBERT
- 다대일
- ORM
- 프론트엔드
- React
- 장고독학
- html
- 플러시
- TODO
- 일대다
- 노마드코더
- 영속성 컨텍스트
- python
- frontend
- nomadcoder
- 매핑
- AWS
- 장고
- 단방향
- web
- java
- css
- 바닐라js
- Django
- 다대다
- JS
- JPA
- 트랜잭션
- clonecoding
- javascript
- Today
- Total
꿈꾸는 새벽하늘
[스타트] 이미지 및 텍스트 분석 기반 실종 반려견 찾기 서비스 본문
이번 학기에 '캡스톤디자인과창업프로젝트A' 수업을 수강하며 스타트 30팀으로 졸업프로젝트를 시작하였다. 수차례의 회의 끝에 우리 팀은 아래와 같은 프로젝트 주제를 선정하였다.
"이미지 및 텍스트 분석 기반 실종 반려견 찾기 서비스"
이 프로젝트의 목표는 3가지이다.
- 보호자의 노력과 목격자의 선의에 기대어 돌아가던 기존 시스템을 알림을 통해 자동화
- 반려견 실종 및 실종·유기견 발견 시 사람들의 다양한 대처 방법을 하나의 플랫폼으로 통일
- 이미지 및 텍스트 분석 기술을 통해 높은 정확도와 빠른 속도로 검색
그리고 이에 따라 궁극적으로는 실종견들이 최대한 빨리 보호자의 품으로 돌아가게 되기를 기대한다.
0. 기술 소개
이 프로젝트의 주요 기능인 이미지 및 텍스트 검색 기능에는 각각 이미지 분석과 텍스트 분석이 이용된다.
(1) 이미지 분석: Keras 라이브러리를 활용한 FaceNet 모델 (Feat. MTCNN)
[참고 논문] FaceNet: A Unified Embedding for Face Recognition and Clustering
이 프로젝트에서는 실종견을 이미지로 검색하여 유사도가 높은 게시물들을 보여주는 기능을 제공하는데, 이 기능에 FaceNet 모델이 가장 적합하다고 판단하였다.
FaceNet은 각각의 얼굴 이미지를 128차원으로 임베딩한 뒤, 유클리드 공간에서 임베딩 벡터들 간의 거리를 통해 분류하는 모델이다. 여기에서 임베딩(Embedding)이란, 얼굴을 표현하는 고차원의 이미지를 필요한 정보를 보존하면서 저차원으로 변환하는 것이다. 이렇게 임베딩한 결과를 유클리드 공간에서 분류할 때 벡터들 간의 거리가 가까울수록 유사도가 높아진다.
FaceNet 모델은 (160 x160)의 일정한 크기의 이미지를 입력받아서 128차원의 임베딩 벡터를 내보낸다. 따라서 다양한 크기의 이미지들을 FaceNet 모델에 적용하기 위해서는 이미지의 얼굴 영역을 일정한 크기와 비율로 변환하는 과정이 필요하다. 이 과정은 MTCNN 모델을 사용하여 효율적으로 처리할 수 있다. MTCNN은 얼굴을 탐지하고 일정한 크기로 변환한 결과를 출력해주는 모델이다.
(2) 텍스트 분석: Sentence-Transformers를 활용한 KLUE/roberta-base 모델
실종견의 특이사항을 작성한 텍스트로 검색하는 기능은 Sentence-Transformers 패키지를 KLUE/roberta-base 모델에 활용하여 구현하기로 결정하였다.
KLUE(Korean Language Understanding Evaluation)는 뉴스 헤드라인 분류, 문장 유사도 비교, 자연어 추론, 개체명 인식, 관계 추출, 형태소 및 의존 구문 분석, 기계 독해 이해, 대화 상태 추적 등 8가지의 한국어 자연어 이해 문제를 포함하고 있는 데이터셋이다. 이 데이터셋은 종류별로 각각의 문장들이 라벨링되어 있다는 장점이 있다. 이 프로젝트에서는 KLUE의 문장 유사도 비교 데이터셋인 STS(Semantic Textual Similarity)를 활용하여 모델을 훈련한다.
Sentence-Transformers는 문장이나 텍스트 임베딩 시 사용하는 Python 프레임워크이다. SBERT라고도 불리는 Sentence-Transformers는 BERT보다 향상된 임베딩 성능을 보여준다.
Sentence-Transformers를 KLUE/Roberta-base 모델에 적용하면 입력한 문장과 데이터셋 내에 있는 문장들 간의 임베딩을 계산하여 유사도를 얻게 된다.
1. 데이터셋 구축
FaceNet 모델과 KLUE 모델 학습을 위해 이미지 데이터셋과 텍스트 데이터셋을 각각 구축하였다.
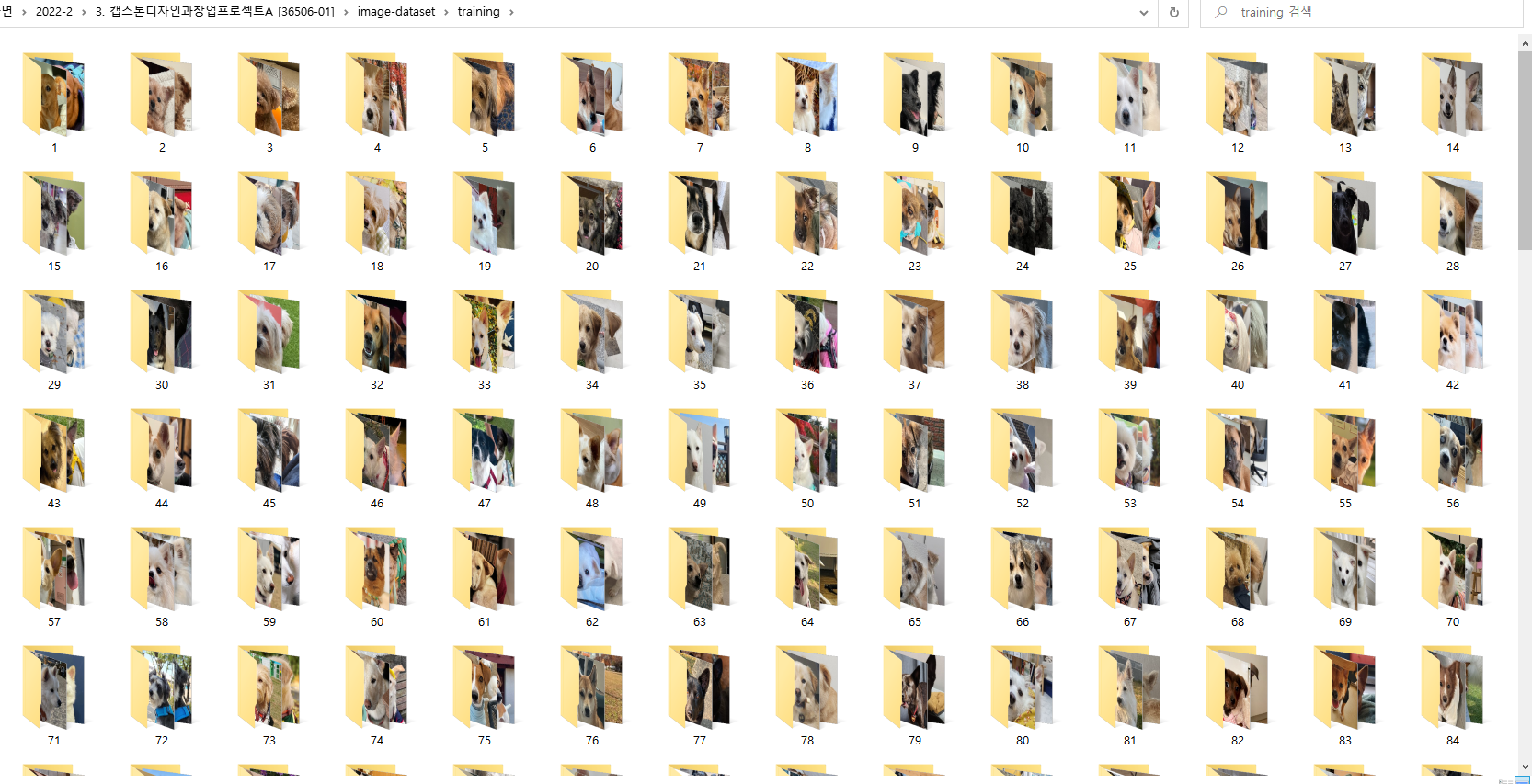
(1) 이미지 데이터셋
이미지 데이터셋은 인스타그램과 트위터 상의 강아지 계정에서 이미지를 추출하여 구축하였다.
처음에는 크롤링으로 이미지를 추출하려 하였으나, SNS 계정에는 강아지의 얼굴이 정확하게 나온 사진뿐 아니라 다른 사진들도 업로드되어 있다는 한계점이 있었다. 따라서 강아지 얼굴이 정확하게 찍힌 사진들만을 따로 저장한 뒤, 동일견들의 사진을 을 한 파일에 저장하는 방식으로 모델 학습용 데이터셋을 구축하였다.
image-dataset 내부에는 training과 test 폴더가 각각 존재한다. training 폴더 안에는 모델 학습용 데이터셋이 구축되어 있고, test라는 폴더 안에는 모델 검증을 위해 강아지 별로 training 폴더 안의 사진과 다른 사진을 하나씩 저장하였다.
(2) 텍스트 데이터셋
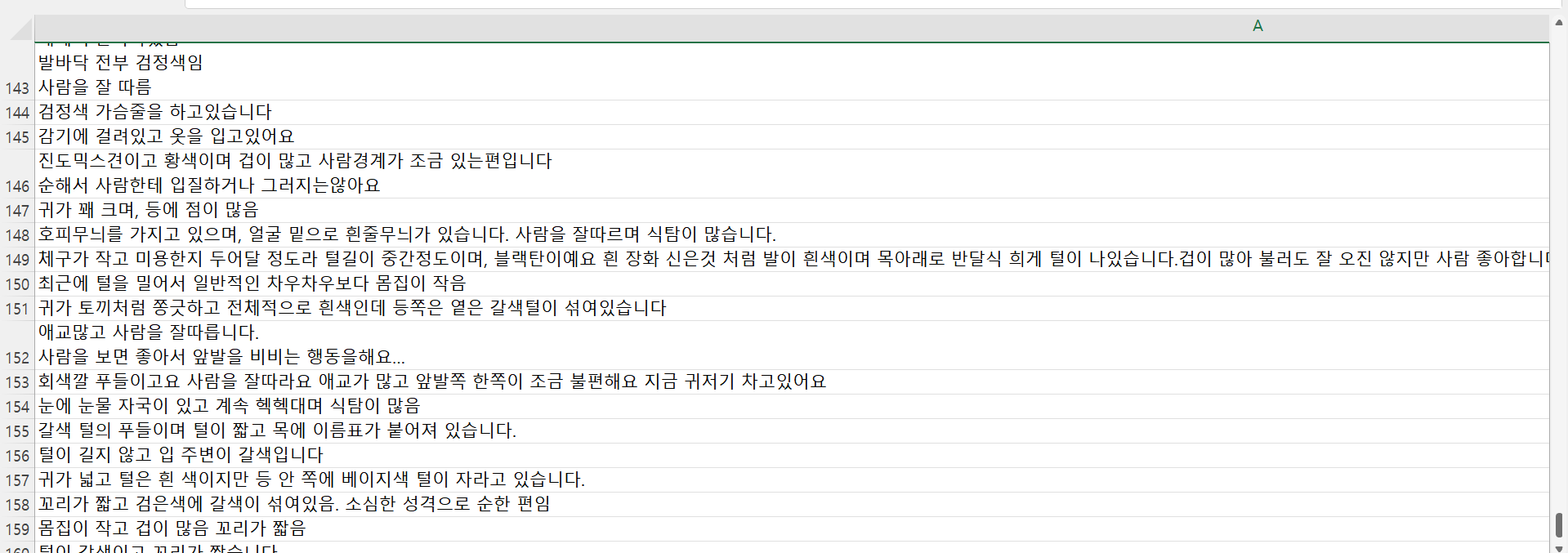
텍스트 데이터셋은 동물보호센터(http://www.angel.or.kr/)와 종합유기견보호센터(https://www.zooseyo.or.kr/) 사이트의 사용자들이 실종/목격/구조 신고를 하면서 작성한 특이사항의 내용을 정리하여 구축하였다.
2. 이미지 탐지 및 변환
이미지 분석을 시작하기 전에, 미리 준비한 image-dataset과 Keras FaceNet을 구글 드라이브에 저장하였다.
# Google Colab에 구글 드라이브 연결
from google.colab import drive
drive.mount('/content/drive')
# mtcnn 패키지와 Keras FaceNet 설치
!pip install mtcnn
!pip install keras-facenet
# 실행에 필요한 패키지 및 라이브러리 불러오기
import mtcnn
import matplotlib.pyplot as plt
from os import listdir
from PIL import Image
from numpy import asarray
from matplotlib import pyplot
from mtcnn.mtcnn import MTCNN
이미지 불러오기
# 데이터셋에서 이미지 불러오기
filename = "/content/drive/MyDrive/dog-faces-dataset/training/004/4.jpg"
pixels = plt.imread(filename)
print("Shape of image/array:",pixels.shape)
imgplot = plt.imshow(pixels)
plt.show()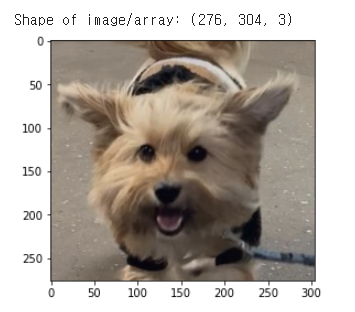
이미지에서 얼굴 탐지하기
# 데이터셋에서 이미지 불러오기
image = Image.open(filename)
# 이미지에 알파 채널이 있거나 이미지가 흑백인 경우 등 필요 시 RGB로 변환
image = image.convert('RGB')
# 배열로 변환
pixels = asarray(image)
detector = MTCNN()
# 이미지에서 얼굴 탐지
results = detector.detect_faces(pixels)
for result in results:
print(result)
이미지에서 얼굴 영역 탐지하고 탐지된 눈, 코, 입 그리기
# 탐지된 물체로 이미지 그리기
def draw_facebox(filename, result_list):
data = plt.imread(filename)
plt.imshow(data)
ax = plt.gca()
for result in result_list:
x, y, width, height = result['box']
rect = plt.Rectangle((x, y), width+30, height,fill=False, color='orange')
ax.add_patch(rect)
for key, value in result['keypoints'].items():
dot = plt.Circle(value, radius=10, color='red')
ax.add_patch(dot)
plt.show()
# 이미지에서 얼굴 영역 탐지하기
faces = detector.detect_faces(pixels)
# 원본 이미지에 탐지된 얼굴 영역 그리기
draw_facebox(filename, faces)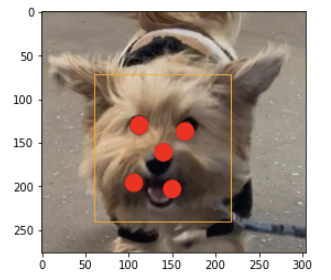
데이터셋에서 탐지된 이미지 변환하며 임베딩하기
# 주어진 사진에서 하나의 얼굴 추출
def extract_face(filename, required_size=(160, 160)):
# 데이터셋에서 이미지 불러오기 - PIL 라이브러리와 open() 함수 이용하여 이미지를 넘파이 배열로 로드
image = Image.open(filename)
# 이미지에 알파 채널이 있거나 이미지가 흑백인 경우 등 필요 시 RGB로 변환
image = image.convert('RGB')
# 배열로 변환
pixels = asarray(image)
# 감지기 생성, 기본 가중치 이용
detector = MTCNN()
# 이미지에서 얼굴 감지
results = detector.detect_faces(pixels)
# 첫 번째 얼굴에서 경계 상자 추출
x1, y1, width, height = results[0]['box']
# 버그 수정
x1, y1 = abs(x1), abs(y1)
x2, y2 = x1 + width, y1 + height
# 얼굴 추출
face = pixels[y1:y2, x1:x2]
# 모델 사이즈로 픽셀 재조정
image = Image.fromarray(face)
image = image.resize(required_size)
face_array = asarray(image)
return face_array
# 이미지 불러와서 얼굴 추출하기
pixels = extract_face('/content/drive/MyDrive/dog-faces-dataset/training/004/1.jpg')
plt.imshow(pixels)
plt.show()
print(pixels.shape)
# 폴더를 플롯으로 구체화하기
folder = '/content/drive/MyDrive/dog-faces-dataset/training/004/'
i = 1
# 파일 나열하기
for filename in listdir(folder):
# 경로
path = folder + filename
# 얼굴 추출
face = extract_face(path)
print(i, face.shape)
# 플롯
pyplot.subplot(2, 2, i)
pyplot.axis('off')
pyplot.imshow(face)
i += 1
pyplot.show()

3. 텍스트 유사도 검증
# sentence-transformers datasets 설치
!pip install sentence-transformers datasets
# 실행에 필요한 패키지 및 라이브러리 불러오기
import math
import logging
from datetime import datetime
import torch
from torch.utils.data import DataLoader
from datasets import load_dataset
from sentence_transformers import SentenceTransformer, LoggingHandler, losses, models, util
from sentence_transformers.evaluation import EmbeddingSimilarityEvaluator
from sentence_transformers.readers import InputExample
Sentence-Transformers 학습시키기
logging.basicConfig(
format="%(asctime)s - %(message)s",
datefmt="%Y-%m-%d %H:%M:%S",
level=logging.INFO,
handlers=[LoggingHandler()],
)
model_name = "klue/roberta-base"
train_batch_size = 32
num_epochs = 4
model_save_path = "output/training_klue_sts_" + model_name.replace("/", "-") + "-" + datetime.now().strftime("%Y-%m-%d_%H-%M-%S")
embedding_model = models.Transformer(model_name)
pooler = models.Pooling(
embedding_model.get_word_embedding_dimension(),
pooling_mode_mean_tokens=True,
pooling_mode_cls_token=False,
pooling_mode_max_tokens=False,
)
model = SentenceTransformer(modules=[embedding_model, pooler])
datasets = load_dataset("klue", "sts")
datasets["train"][0]
testsets = load_dataset("kor_nlu", "sts")
testsets["test"][0]
train_samples = []
dev_samples = []
test_samples = []
# KLUE STS 내 훈련, 검증 데이터 예제 변환
for phase in ["train", "validation"]:
examples = datasets[phase]
for example in examples:
score = float(example["labels"]["label"]) / 5.0 # 0.0 ~ 1.0 스케일로 유사도 정규화
inp_example = InputExample(
texts=[example["sentence1"], example["sentence2"]],
label=score,
)
if phase == "validation":
dev_samples.append(inp_example)
else:
train_samples.append(inp_example)
# KorSTS 내 테스트 데이터 예제 변환
for example in testsets["test"]:
score = float(example["score"]) / 5.0
if example["sentence1"] and example["sentence2"]:
inp_example = InputExample(
texts=[example["sentence1"], example["sentence2"]],
label=score,
)
test_samples.append(inp_example)
train_dataloader = DataLoader(
train_samples,
shuffle=True,
batch_size=train_batch_size,
)
train_loss = losses.CosineSimilarityLoss(model=model)
evaluator = EmbeddingSimilarityEvaluator.from_input_examples(
dev_samples,
name="sts-dev",
)
warmup_steps = math.ceil(len(train_dataloader) * num_epochs * 0.1) # 10% of train data for warm-up
logging.info(f"Warmup-steps: {warmup_steps}")
model.fit(
train_objectives=[(train_dataloader, train_loss)],
evaluator=evaluator,
epochs=num_epochs,
evaluation_steps=1000,
warmup_steps=warmup_steps,
output_path=model_save_path,
)
model = SentenceTransformer(model_save_path)
test_evaluator = EmbeddingSimilarityEvaluator.from_input_examples(test_samples, name='sts-test')
test_evaluator(model, output_path=model_save_path)
검색의 대상이 되는 문장들 임베딩하기
docs = [
"귀가 토끼처럼 쫑긋하고 전체적으로 흰색인데 등쪽은 옅은 갈색털이 섞여있습니다",
"귀가 꽤 크며, 등에 점이 많음",
"갈색 털의 푸들이며 털이 짧고 목에 이름표가 붙어져 있습니다.",
"털이 길지 않고 입 주변이 갈색입니다",
"귀가 넓고 털은 흰 색이지만 등 안 쪽에 베이지색 털이 자라고 있습니다.",
"꼬리가 짧고 검은색에 갈색이 섞여있음. 소심한 성격으로 순한 편임",
"몸집이 작고 겁이 많음 꼬리가 짧음"
]
document_embeddings = model.encode(docs)
검색하는 문장 임베딩하기
query = "털이 갈색이고 꼬리가 짧습니다."
query_embedding = model.encode(query)
입력한 문장과 데이터셋 내에 있는 문장들 간의 임베딩을 계산하여 유사도 구하기
top_k = min(5, len(docs))
# 입력 문장 - 문장 후보군 간 코사인 유사도 계산 후,
cos_scores = util.pytorch_cos_sim(query_embedding, document_embeddings)[0]
# 코사인 유사도 순으로 `top_k` 개 문장 추출
top_results = torch.topk(cos_scores, k=top_k)
print(f"입력 문장: {query}")
print(f"\n<입력 문장과 유사한 {top_k} 개의 문장>\n")
for i, (score, idx) in enumerate(zip(top_results[0], top_results[1])):
print(f"{i+1}: {docs[idx]} {'(유사도: {:.4f})'.format(score)}\n")
4. 추후 계획
이미지 분석의 경우 동일견 별로 더 많은 사진을 저장하는 작업을 통해 풍부한 이미지 데이터셋을 확보하여 FaceNet 모델의 얼굴 유사도를 높일 것이다. 그리고 MTCNN 모델을 활용하여 데이터셋의 얼굴 영역을 일정한 크기와 비율로 변환한 뒤, FaceNet 모델에 적용하여 클러스터링할 예정이다. 이후 유사도 향상을 위해 끊임없이 모델을 공부하고 학습시키며 프로젝트를 완성해나가고자 한다.
텍스트 분석의 경우 이번에는 기술 검증을 위해 텍스트 데이터셋에서 몇 개의 문장만을 추출하여 모델을 학습시켰다. 이제 다음 단계에서는 Google Colab에 텍스트 데이터셋을 연결하여 임베딩을 계산하고 유사도를 비교할 것이다.
이 서비스는 사용자들의 접근성을 고려하여 반응형 웹으로 구현하기로 하였다. 따라서 기술의 정확도를 높이는 동시에 웹 개발에 있어서 각자 맡은 파트를 공부하고 개발해나갈 것이다. 내가 맡은 파트는 백엔드이고, 앞으로 데이터베이스 설계와 API 구축 등을 공부하면서 개발을 진행할 예정이다.
'🌸 Capstone Design Project' 카테고리의 다른 글
| [그로쓰] 이미지 및 텍스트 분석 기반 실종 반려견 찾기 서비스 (1) | 2023.05.16 |
|---|
